Recommendation systems: all you need to know about the two main approaches
Many products we buy have been suggested by recommendation systems, what are the main approaches? Let’s find out how they work!
Recommendation systems: all you need to know about the two main approaches
Many products we buy have been suggested by recommendation systems, what are the main approaches? Let’s find out how they work!
Nowadays, many products we choose have actually been suggested to us by the so-called recommendation systems.
How do they recommend to us what is in line with our tastes? The role of Artificial Intelligence and data is crucial. Let’s find out why.
What are the recommendation systems?
Have you recently purchased a product you thought you didn’t need? Or have you ever bought a product you didn’t really need? You have been a victim of marketing or rather of Artificial Intelligence.
Sending suggestions on products of interest to you is, in fact, the goal of the famous recommendation systems, or recommender systems. What are they and how exactly do they work?
We can start first by getting to know them from a marketing perspective.
Recommender systems are used to make it easier for users to explore the items available to them, from movies to restaurants to order from. Therefore, on the one hand, its use improves user satisfaction and on the other hand, it brings economic benefits to the service provider.
The widespread use of these systems is precisely due to the need for mass customization. Companies, in fact, want to offer their customers what they want when the need arises. Because of its nature, a recommendation system makes it possible to simplify the consumer’s decision making process.
How is it possible to provide targeted suggestions on what to buy?
Recommendations, indeed, are based on various different factors, such as past purchases and search history. Here comes the importance of Artificial Intelligence.
So, a recommendation system is a set of machine learning (ML) techniques, which uses big data to suggest or to recommend products to consumers at a highly personalized level.
It is trained to understand the preferences, previous decisions and features of people and products. This is possible by collecting data on their interactions, such as impressions, clicks, likes and of course purchases.
Then, items are ranked according to their relevance. The most relevant ones are shown to the user. It is no wonder that yesterday you looked at sneakers on a fashion app and in the next few days it will start showing you many pairs of similar sneakers and shoes.
The way the algorithm works might seem similar to continuous machine learning, which we have already talked about. The recommendation system is definitely different and more structured.
Do you want to know why?
We anticipate that there are two main categories within recommender systems. Are you curious about them?
The two main approaches of recommendation systems
Recommender systems are generally divided into collaborative filtering systems and content-based systems.
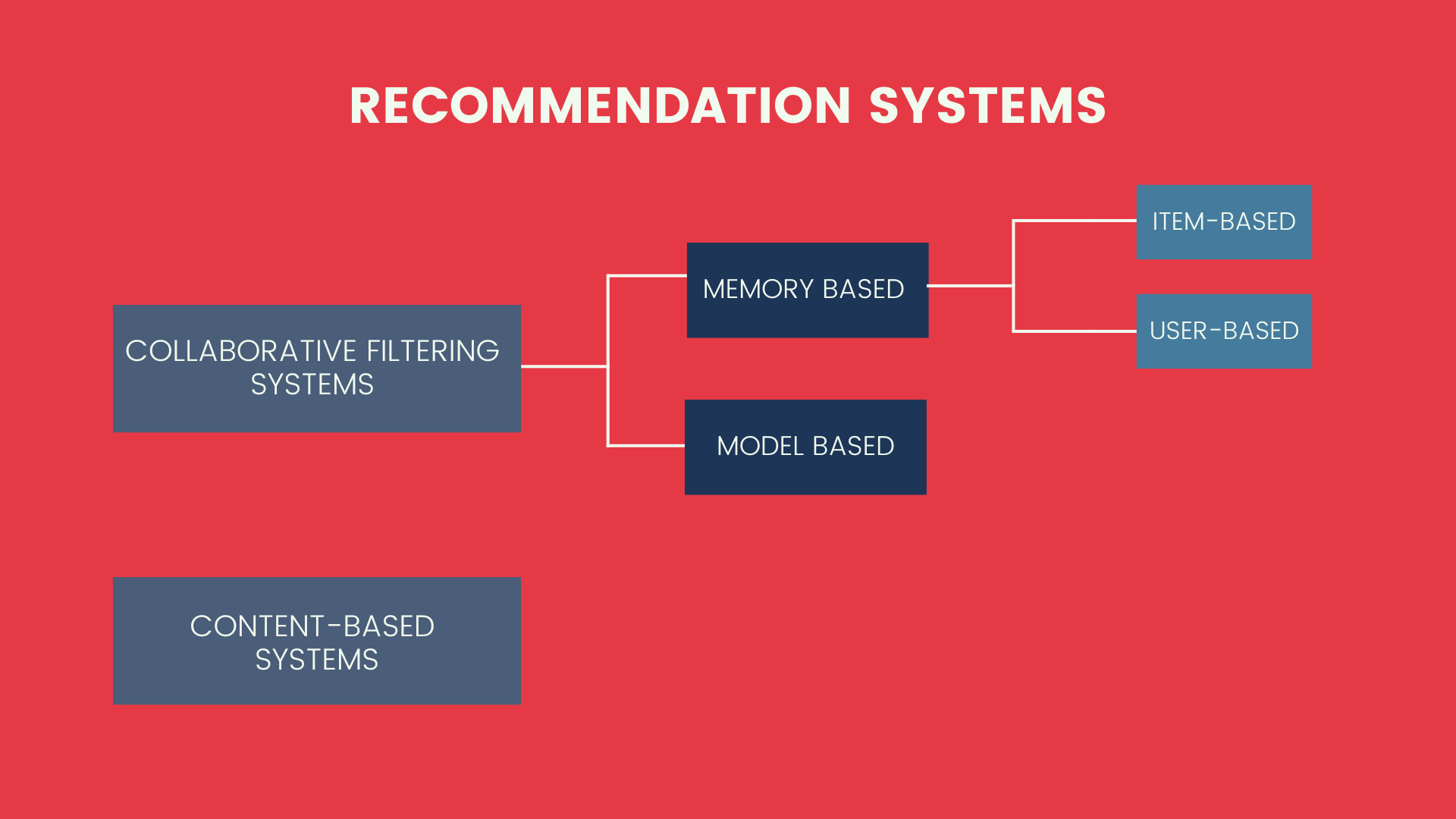
The first system, which we will now learn about, contains several models. In the following image we provide a brief introduction.
|
Main approaches of recommendation systems |
Collaborative Filtering Systems
Collaborative filtering methods use ML algorithms to filter data from past interactions between users and target elements. These interactions form the historical data, which are typically stored in a matrix in which the rows are the users and the columns are the elements.
As we mentioned before, collaborative filtering systems are further divided into two subgroups: memory-based methods and model-based methods. Let’s get to know them.
Memory-based methods usually take collected data as input and compute recommendations on the entire dataset of people using similarity metrics.
Model-based approaches, using ML algorithms, build a model from a training-set and validate it on test data. In this case, only a portion of the users are considered to build the model.
Following the diagram in the image, we note that memory-based methods include, in addition, user-based and item-based methods. They differ in the technique used to identify similarities between users and/or items.
In detail, user-based methods represent users by considering their interactions with items. Algorithms, in fact, evaluate the similarity between one user and another. Generally, two users are considered similar if they have interacted with many items in the same way. The new recommendation to a user will be generated by identifying those with the most similar “interaction profiles” to his or her own.
An example of a user-based method, that we all deal with every day, is Youtube when it suggests videos.

In the case of item-based methods, ML algorithms analyze items based on the interactions users had with them.
Two items are considered similar if the majority of users who interacted with both did so in the same way. When making a new recommendation to a user, these methods consider items similar to those with which the user has interacted positively.
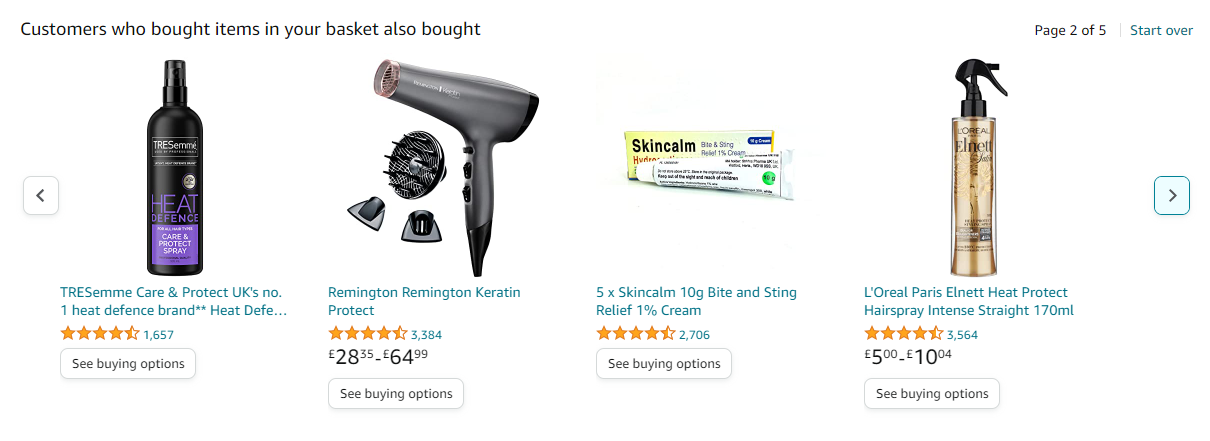
This is the AI method used by Amazon when, for example, we add an item to the basket. The section “customers who bought the item in your cart also bought” will immediately appear, showing us other items similar to the one we selected.
Let’s continue now to the second most important recommendation system.
Content-based Systems
Compared with collaborative filtering recommendation systems, content-based approaches examine additional information to make predictions. For example, this filtering method might consider the user’s age, gender, occupation and other personal factors.
Content-based methods build a model that can explain the user-article interaction matrix based on the features available to users and articles.
In concrete terms, you need the model that explains how users with certain features like, for example, videos with as many features. Once this model has been obtained, making predictions for a new user is easy.
Pros and cons of both approaches
We finally learned how the two most important approaches of recommender systems work. Is one system better than the other?
There is no correct answer, because each system, beyond its functionality, has strengths and weaknesses that should not be underestimated. Are you aware of these?
We present them briefly.
The main advantage of collaborative filtering systems is that they don’t require extraction of information about users or articles. Therefore they can be used in a variety of contexts. In addition, the more users interact with the articles, the more information will be available and the more accurate the new recommendations will be.
Their disadvantage emerges when you have new users or new articles, because there is no past information about their interactions. In this case different practices are adopted to make the new recommendations, for example, randomly chosen articles are recommended to new users or new articles to randomly chosen users.
In contrast, with regard to content-based systems, it does not need data on other users, since the recommendations are specific to this user. This allows it to scale more easily to a large number of users. In addition, the model can collect a user’s specific interests and recommend items that very few users are interested in.
This technique, however, requires a lot of domain-related knowledge, since the representation of items is customized. In addition, the model can only make suggestions based on the user’s existing interests, so it has limited ability to broaden the interests of existing users.
The choice of approach depends on the willingness and goal that the service or product provider intends to achieve.
Who knows what the future of personalized recommendations will be. Will there be even more accurate and personalized systems in the future?
© Copyright 2012 – 2023 | All Rights Reserved
Author: Niccolò Cacciotti, Head of AI Department
Nowadays, many products we choose have actually been suggested to us by the so-called recommendation systems.
How do they recommend to us what is in line with our tastes? The role of Artificial Intelligence and data is crucial. Let’s find out why.
What are the recommendation systems?
Have you recently purchased a product you thought you didn’t need? Or have you ever bought a product you didn’t really need? You have been a victim of marketing or rather of Artificial Intelligence.
Sending suggestions on products of interest to you is, in fact, the goal of the famous recommendation systems, or recommender systems. What are they and how exactly do they work?
We can start first by getting to know them from a marketing perspective.
Recommender systems are used to make it easier for users to explore the items available to them, from movies to restaurants to order from. Therefore, on the one hand, its use improves user satisfaction and on the other hand, it brings economic benefits to the service provider.
The widespread use of these systems is precisely due to the need for mass customization. Companies, in fact, want to offer their customers what they want when the need arises. Because of its nature, a recommendation system makes it possible to simplify the consumer’s decision making process.
How is it possible to provide targeted suggestions on what to buy?
Recommendations, indeed, are based on various different factors, such as past purchases and search history. Here comes the importance of Artificial Intelligence.
So, a recommendation system is a set of machine learning (ML) techniques, which uses big data to suggest or to recommend products to consumers at a highly personalized level.
It is trained to understand the preferences, previous decisions and features of people and products. This is possible by collecting data on their interactions, such as impressions, clicks, likes and of course purchases.
Then, items are ranked according to their relevance. The most relevant ones are shown to the user. It is no wonder that yesterday you looked at sneakers on a fashion app and in the next few days it will start showing you many pairs of similar sneakers and shoes.
The way the algorithm works might seem similar to continuous machine learning, which we have already talked about. The recommendation system is definitely different and more structured.
Do you want to know why?
We anticipate that there are two main categories within recommender systems. Are you curious about them?
The two main approaches of recommendation systems
Recommender systems are generally divided into collaborative filtering systems and content-based systems.
The first system, which we will now learn about, contains several models. In the following image we provide a brief introduction.
|
Main approaches of recommendation systems |
Collaborative Filtering Systems
Collaborative filtering methods use ML algorithms to filter data from past interactions between users and target elements. These interactions form the historical data, which are typically stored in a matrix in which the rows are the users and the columns are the elements.
As we mentioned before, collaborative filtering systems are further divided into two subgroups: memory-based methods and model-based methods. Let’s get to know them.
Memory-based methods usually take collected data as input and compute recommendations on the entire dataset of people using similarity metrics.
Model-based approaches, using ML algorithms, build a model from a training-set and validate it on test data. In this case, only a portion of the users are considered to build the model.
Following the diagram in the image, we note that memory-based methods include, in addition, user-based and item-based methods. They differ in the technique used to identify similarities between users and/or items.
In detail, user-based methods represent users by considering their interactions with items. Algorithms, in fact, evaluate the similarity between one user and another. Generally, two users are considered similar if they have interacted with many items in the same way. The new recommendation to a user will be generated by identifying those with the most similar “interaction profiles” to his or her own.
An example of a user-based method, that we all deal with every day, is Youtube when it suggests videos.
In the case of item-based methods, ML algorithms analyze items based on the interactions users had with them.
Two items are considered similar if the majority of users who interacted with both did so in the same way. When making a new recommendation to a user, these methods consider items similar to those with which the user has interacted positively.
This is the AI method used by Amazon when, for example, we add an item to the basket. The section “customers who bought the item in your cart also bought” will immediately appear, showing us other items similar to the one we selected.
Let’s continue now to the second most important recommendation system.
Content-based Systems
Compared with collaborative filtering recommendation systems, content-based approaches examine additional information to make predictions. For example, this filtering method might consider the user’s age, gender, occupation and other personal factors.
Content-based methods build a model that can explain the user-article interaction matrix based on the features available to users and articles.
In concrete terms, you need the model that explains how users with certain features like, for example, videos with as many features. Once this model has been obtained, making predictions for a new user is easy.
Pros and cons of both approaches
We finally learned how the two most important approaches of recommender systems work. Is one system better than the other?
There is no correct answer, because each system, beyond its functionality, has strengths and weaknesses that should not be underestimated. Are you aware of these?
We present them briefly.
The main advantage of collaborative filtering systems is that they don’t require extraction of information about users or articles. Therefore they can be used in a variety of contexts. In addition, the more users interact with the articles, the more information will be available and the more accurate the new recommendations will be.
Their disadvantage emerges when you have new users or new articles, because there is no past information about their interactions. In this case different practices are adopted to make the new recommendations, for example, randomly chosen articles are recommended to new users or new articles to randomly chosen users.
In contrast, with regard to content-based systems, it does not need data on other users, since the recommendations are specific to this user. This allows it to scale more easily to a large number of users. In addition, the model can collect a user’s specific interests and recommend items that very few users are interested in.
This technique, however, requires a lot of domain-related knowledge, since the representation of items is customized. In addition, the model can only make suggestions based on the user’s existing interests, so it has limited ability to broaden the interests of existing users.
The choice of approach depends on the willingness and goal that the service or product provider intends to achieve.
Who knows what the future of personalized recommendations will be. Will there be even more accurate and personalized systems in the future?
© Copyright 2012 – 2023 | All Rights Reserved
Author: Niccolò Cacciotti, Head of AI Department











Leave A Comment